Mittwoch und Donnerstag habe ich an der ERworld teilgenomnen – quasi eine Hausmesse von Computer Associates zur Software ERwin. Nachfolgend ein paar Zeilen zu den Neuigkeiten der gerade veröffentlichten Version r9.6.
Wenn man die Agenda studiert, wird schnell klar, wohin die Reise geht. CA will das marktführende Datenmodellierungswerkzeug zu einer Data-Management-Plattform ausbauen. Das Mega-Thema lautet „Data-Governance“. Und gleich dahinter – „Big-Data“. Bei beiden Blockbuster-Themen spielt das bereits eingeführte Produkt „ERwin-Webportal“ eine strategische Rolle. Die Fremdsoftware „Meta Integration“ wurde bereits für die ERwin-Version r9.5 nahtlos mit ERwin-Data-Modeler integriert. Jetzt wird nochmals ordentlich „nachgelegt“: Unter dem neuen Oberflächen-Design („flat-design“) stehen mächtige neue Funktionen und Werkzeuge parat.
Bereits seit Version r9.5 stehen über das Web-Portal sehr interessante Funktionen zur Verfügung, die ERwin-Data-Modeler als (Stand-Alone-) Desktop-Applikation nicht leisten kann:
- Modellübergreifende Analysen, unterstützt durch eine Volltext-Suche
- Web-basierter Zugriff.
- Modellübergreifende Darstellung einer Data-Lineage. Für den Data-Warehouse-Bereich sehr interessant, um den Datenfluss vom operativen Quellsystem über verschiedene Schichten des Core-Warehouse bis zur Data-Mart-Ebene darstellen zu können. Auf diese Weise können Impact-Analysen von Business-Analysten oder dem Fachbereich gefahren werden, um zum Beispiel sehr schnell einschätzen zu können, welchen Aufwand eine Änderung im Quellsystem über alle BI-Schichten des Data-Warehouse verursacht – oder umgekehrt: Der Fachanwender kann nachvollziehen, aus welchen Quellsystem-Attributen sich seine im Front-End angezeigte Kennzahl zusammensetzt. In beiden Fällen stehen alle Metadaten, die in ERwin erhoben wurden, zur Verfügung (keine Informationsverlust). Alle Attribut-Informationen sind ferner mit den aus ERwin übernommenen Diagrammen verlinkt. So kann mit einem Klick von einem Analyse-Ergebnis direkt ins Diagramm gesprungen werden. Das entsprechende Attribut im Diagramm wird markiert und die zugehörigen Metadaten angezeigt. Basis für diese Darstellungsmöglichkeit ist die Abbildung einer logischen Target-to-Source-Zuordnung im ERwin-Modell via Column-Editor. Siehe hierzu auch folgenden Webcast
- Zeitgesteuerte Uploads von Modellen von Erwin zum Web-Portal

Diese bereits sehr wertvollen Funktionsergänzungen zu Erwin-Data-Modeler via Web-Portal, erweitert CA nun erheblich mit Einführung der neuen „Data Governance Edition“. Die nachfolgende Übersicht zeigt den erweiterten Funktionsumfang im Vergleich.

Neil Buchwalter, Produktmanager von ERwin, erklärte und demonstrierte in einer Live-Demo die strategischen Highlights:
Web Metadata Authoring Tools
Bisher konnte das Web-Portal ausschließlich Metadaten anzeigen, die bereits in ERwin-Data-Modeler oder anderen Metadaten-Quellen erhoben wurden. Neu ist, das Anwender jetzt Daten über das Portal eingeben bzw. pflegen können. Das Web-Portal wird also zu einer operativen Anwendung.
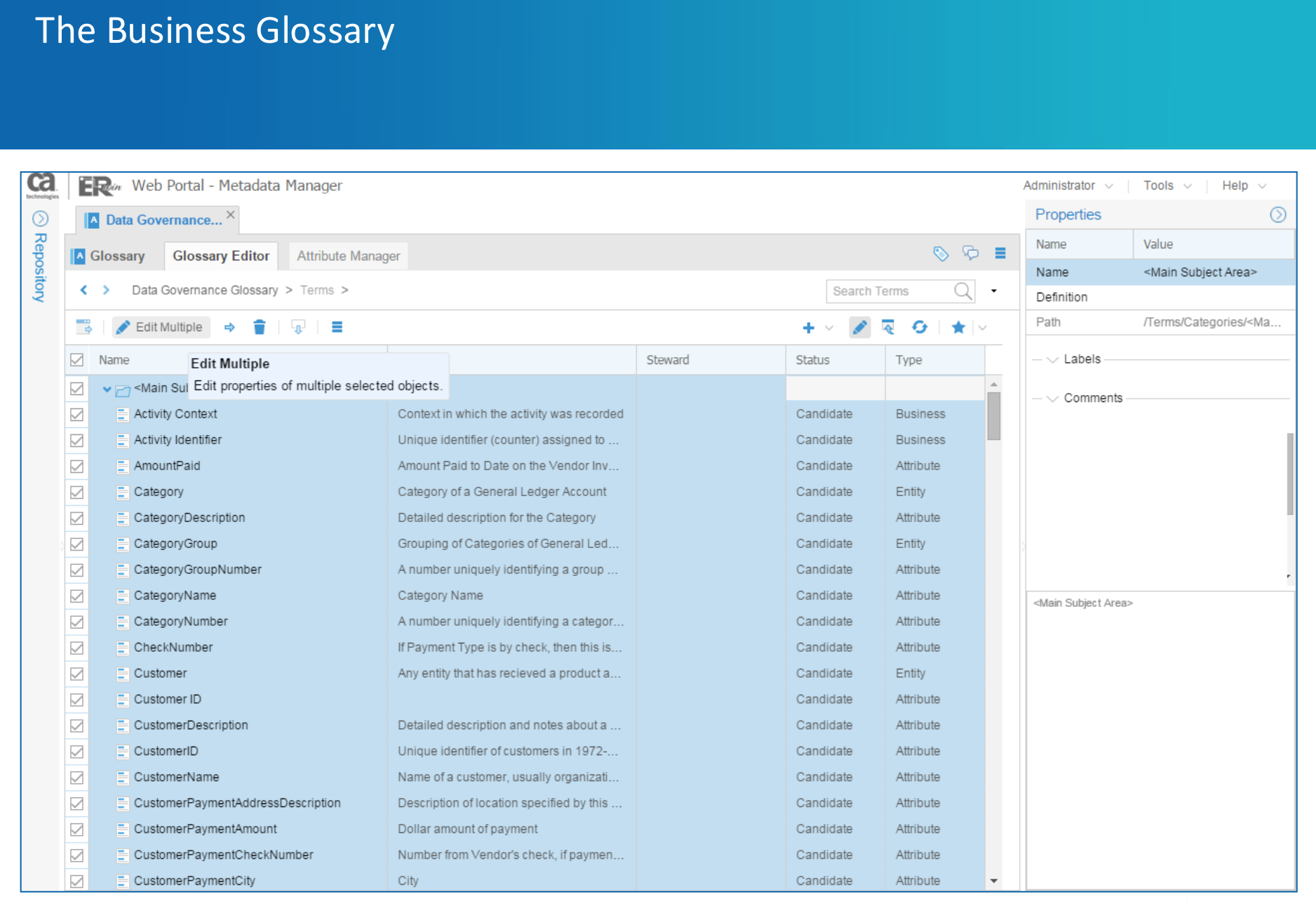
Business Glossary: Basierend auf ISO-Standard ISO-11179 enthält die Data-Governance-Edition eine Anwendung zur Pflege von fachlichen Begriffen des Unternehmens. Initial kann das Glossary mit den logischen Namen eines ERwin-Modells gefüllt werden. Anschließend können Anwender die fachlichen Begriffen „unabhängig“ von ERwin-Modellen pflegen, freigeben und untereinander verlinken, Hierarchien und zugehörige Business-Rules abbilden und vieles mehr. Auch eine Verlinkung auf ERwin-Modelle ist möglich bzw. bleibt erhalten.
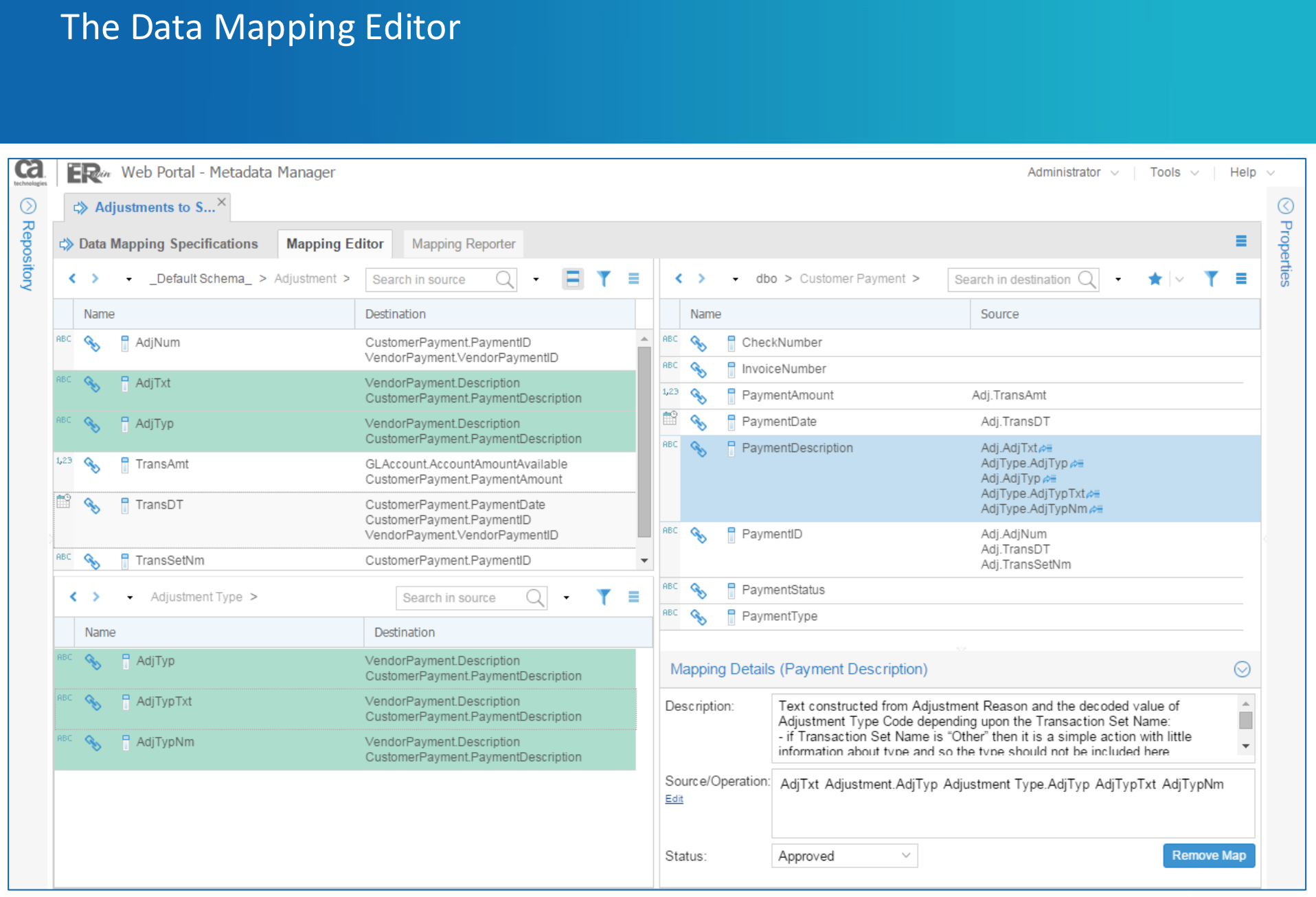
Semantic Mapper: Diese neue Anwendung erlaubt es endlich die für den Data-Warehouse-Kontext so wichtige Verlinkung von Modellen, die strukturell völlig unterschiedlich sein können. Beispielsweise sieht in der Regel ein konzeptionelles Modell komplett anders aus als ein Data-Vault-Datenmodell, ein multi-dimensionales Modell sieht wiederum komplett anders aus. Alle Daten basierten jedoch auf der gleichen Quelle – dem operativen Vorsystem. Die „historische“ Verlinkungsfunktion von ERwin (logical-physical) konnte das nie leisten. Darüber hinaus, kann der Modellierer nun auch das Business-Glossary mit Datenmodellen verlinken. Mit dem „Data-Mapper“ definiert er „Target-to-source-Mappings“. Bisher war dies nur auf eine Weise möglich: In ERwin-Data-Modeler unter Verwendung von Data-Warehouse-Sources und die entsprechende Referenzierungsangabe auf der Registerkarte „Data Source“ im Column-Editor-Dialg. Nun definiert der Modellierer davon unabhängig Mappings auch im Web-Portal. Dies erweitert die Einsatzszenarien erheblich. So ist die Verlinkung mit Front-End-Metadaten denkbar.

Data Documenter: Ehrlich gesagt, habe ich noch nicht richtig verstanden, was dieses Tool leisten soll ;-). Neil Buchhalter: „Live”business glossary driven modeling of web-based data store diagrams“…?
Universal Data Modeling: Auch dieses neue Feature ermöglichst gänzlich neue Einsatzmöglichkeiten. Metadaten-Modelle fremder Tool-Hersteller lassen sich nun integrieren und semantisch mit ERwin-Modellen verlinken. Darüber hinaus sind Direktzugriffe („Live-Access“) auf Metadaten-Repositories anderer Hersteller wie z.B. Informatica oder IBM möglich. Vorteil der Live-Anbindung: Aktuellste Metadaten.
Erweiterte Datenbank-Unterstützung inkl. BIG-Data-Stores
- Relationale Datenbanken: IBM DB2 & Netezza, Microsoft SQLServer, Oracle, Pivotal Greenplum, PostgreSQL, and Teradata
- Big-Data: Hadoop Distributions – inkl. Cloudera, DataStax, Hortonworks, MapR; Vertica, AmazonRedShift und NoSQL-Datenbanken wie MongoDB, Couchbase, Cassandra, Neo4J
- In-Memory Datenbanken wie SAP HANA, VoltDB, SQLServer Hekaton, Oracle, DB2 BLU
- Third-Party-Modellierungswerkzeuge wie Embarcadero ER/Studio Data Modeler, IBM InfoSphere Data Modeler, Oracle SQL Developer Data Modeler, SAP Sybase PowerDesigner
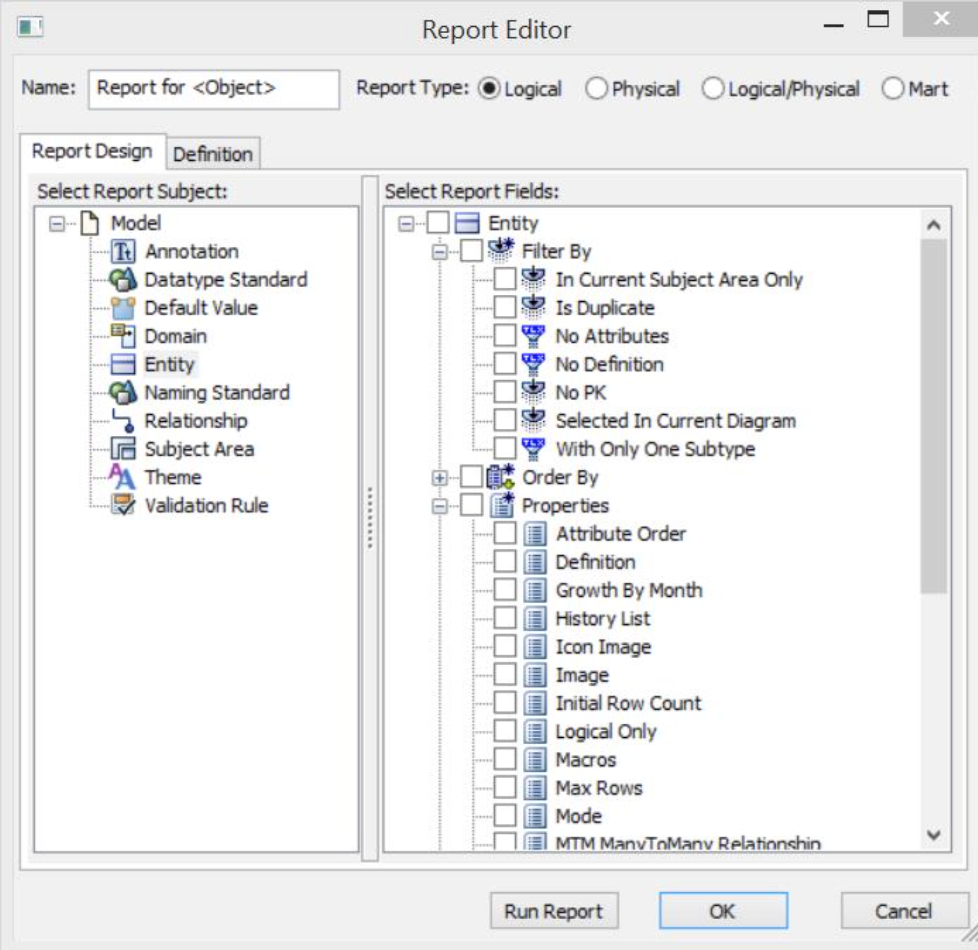
Stark erweiterte Report-Funktionen
Ein weiterer Bereich, der in Version r9.6 wesentlich verbessert wurde, ist das Reporting. ERwin-Data-Modeler liefert nun ca. 100 fertige Berichte „out-of-the-box“. Darunter eine Vielzahl von „Validation-Reports“. Diese dienen der Qualitätssicherung. Der Clou aber ist, dass nun die Informationsobjekte des Report-Designer über die interne Macro-Sprache TLX erweiterbar sind – auch um berechenbare Informationen, z.B. Anzahl Entities pro Modell.
Von Bedeutung: Jetzt sind auch modellübergreifende Reports mit Report-Designer möglich. Auch administrative Informationen über den Zustand des Repositories (MartServer) wie z.B. User, Locks, etc. lassen sich abrufen.
PDF-Dokumente erstellt Erwin nun inkl. verlinktem Index. Auf diese Weise entstehen „interaktive“ PDF-Berichte durch die man per Klicks navigieren kann.
Ansonsten gibt es noch kleinere Verbesserungen bzgl. User-Interface, z.B. UDP-Editor, Mart-Model-Open-Dialog u.a.
Universal-Modeling
Allen Wang stellte in seinem Vortrag vor, wie Datenstrukturen bzw. Inhalte zwischen verschiedenen Datenbanktechnologien ausgetauscht werden können. Scheinbar plant CA eine Art „Middleware“-Komponente zwischen der RDBMS und der NoSQL-Welt einzusetzen. Diese befindet sich jedoch noch im Prototype-Stadium. Mit diesem Werkzeug soll ein Schema-Reverse-Engineering von NoSQL nach RDBMS (ERwin Data Modeler) möglich sein und vice-versa. Mein persönlicher Eindruck: „Sieht noch sehr nach Prototyp aus“.
Modellierungsstandards und ERwin-Data-Modeler
Vortragsredner Joseph Maggi beschäftigte sich mit der Durchsetzung von Entwicklungsstandards, die auch bzw. gerade in agilen Projekten von besonderer Bedeutung sind. Nachdem die grundsätzlichen ERwin-Features in diesem Kontext vorgestellt wurden, demonstrierte er in einer Demo, wie durch den geschickten Einsatz von Domains und EML-Macros sich der Modellierungsprozess vereinfachen lässt und wie dies gleichzeitig die Qualität der Metadaten und die Konsistenz der Modelle steigert.
Mein Fazit: Informative Veranstaltung und bzgl. Produktneuigkeiten: Die Data-Governance-Offensive von CA ERwin klingt sehr sehr vielversprechend!